Thursday night I was shutting down AWS instances on which I had enabled termination protection. Since automation is useless when confronting termination protection, I went old-school and disabled termination protection one instance at a time through the AWS Console. The experience brought back memories of my first encounter with cloud fratricide (a.k.a. friendly fire incidents in the cloud).
The Incident
It was late evening when one of our search clusters had gone into a degraded state. The on-call engineer concluded the cluster was being overloaded and recommended a routine operation: adding four nodes to the cluster. We called in a DevOps engineer to execute the plan, and here is a rough replay of what happened next:
Me: “Why do I see more than four nodes just launched.”
DevOps Engineer: “Some nodes failed to bootstrap, so I launched new ones. Want me to shut them down?”
Me: “Yeah.”
DevOps Engineer: “Doing that now.”
(...about 30 seconds later...)
Developer #1: “I’m seeing an issue with one of the nodes in the cluster.”
Developer #2: “Me too.”
Developer #1: “Master node just disappeared.”
Developer #2: “Just lost the node I was on too.”
Another 30 very long seconds later we learned the DevOps engineer fat fingered his way to terminating a cluster containing the full text indices for over a billion documents. While we recovered from the incident after a long night, I learned a lesson that would not soon be forgotten.
The Root Cause
We are at a higher risk of friendly fire incidents in the cloud for the following reasons:
- Cloud APIs - The cloud enables us to make almost any change to our infrastructure through an API call. The same code that allows you to spin up any number of nodes in a matter of minutes, also allows you to shut down your entire infrastructure with a short script.
- Dynamic infrastructure - Well designed cloud infrastructure is dynamic, requiring a pace of change that challenges the throughput of traditional change management processes. It is not uncommon for a sophisticated cloud application to have changes to 10%+ of its assets every single day.
- Infrastructure as code - To manage this pace of change, we require automation to ensure the consistent execution of mass changes. This automation is at risk of both defects and intentional / unintentional misuse.
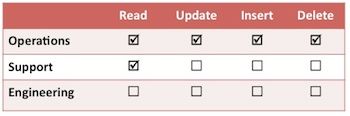
- Centralization of escalated privileges - We have increasingly centralized the escalated privileges into small DevOps or operations teams. These teams have one critical flaw: they are human. ;)
The Solution
I have long aspired to task-based access control, where a change management system automatically grants least privilege for specific scoped tasks, then revokes these privileges based on pre-defined triggers (e.g. time). Unfortunately even Amazon, which is ahead of its competitors in access control by at least 2-3 years, does not have the full semantics to support this type of system. In the meantime, assess the risk, tighten your access control, review your change processes, and take advantage of crude but effective features such as termination protection to avoid your own friendly fire incident.
Related Posts: What To Do In Response To Code Spaces