Introduction

My QA manager from SilverBack used to talk about the servers in our labs like children. There were the servers that away did what they were asked, performing reliably whenever called upon. But there were also the troublesome servers that acted out whenever an opportunity would arise.
What he knew through intimate familiarity with his lab was that all servers were not equal, regardless of their specification or configuration. Whether due to hardware, firmware, operating system, application or even its location in the network, systems of the same specification do not always perform equally.
Today I set out to demonstrate the equivalent performance variability within cloud computing.
Methodology
To prove or disprove performance variability, I designed a scoped test that involved running selected benchmark tools on equivalent servers launched in the cloud. The chosen benchmarks include:
CPU - smallpt uses the Monte Carlo path tracing algorithm to test the processor performance.
Memory - ramspeed tests the performance of the cache and memory subsystems.
Disk - hdparm was used to perform disk read tests.
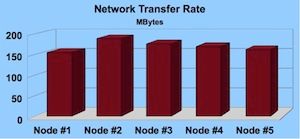
Network - iperf was used to get transfer and bandwidth from each node to a selected server (the target server was hosted by a separate provider).
I chose Amazon for the test, since it is the cloud computing gold standard. All instances were launched simultaneously to avoid an instance being recycled, and were launched in the US east region. The selected instances were of size m1.large, which in EC2 are configured with 7.5 GB memory, 2 virtual cores, 850 GB instance storage, and 64-bit. I ran Ubuntu 10.10 on each server, and attached an 8 GB Elastic Block Storage volume to allow me to test performance of both ephemeral (local) and non-ephemeral storage (attached).
Results
While the data sample is too small to draw broad conclusions, it did provide some interesting results. For example, CPU, memory and local disk (ephemeral) performance across all nodes were mostly uniform, with min/max performance deviating by no more than 3% (CPU varied by 0.6%, memory varied by 2.9%, ephemeral storage varied by 2.7%).
We saw much greater variability in the performance of our attached storage (EBS) and network, with attached storage min/max performance varying by 8.0%, and network transfer varying by 17.9%. In addition, these were not simply point in time variations, but could be reproduced, suggesting some difference in the underlying virtual or physical infrastructure.
The below table provides the detailed results:
[table id=7/]
Conclusions
While variability in cloud performance is not going to come as a shock to any of us, its implications can be profound. For example, a newly provisioned node in the cloud may be less performant than others for a number of reasons (e.g. shared load on host, different hardware components, performance of storage or network). In addition, some nodes will quite simply be "bad" - never providing good performance at any time in their lifespan.
But while the non-performant nodes in our physical labs can be uniquely identified by their name, location or even serial number, a "bad" node in the cloud is virtually unidentifiable through any means short of a performance test. So while provisioning a cloud resource is fast and easy, it comes with a responsibility to trust but verify the quality of the resources you are using.
I leveraged official Ubuntu Amazon Machine Instances, and ran my tests using Phoronix Test Suite. I'd be happy to share additional test details with anyone interested. My Amazon bill for this post was $2.70.